

Yesterday, a friend mentioned that he’s organizing a hackathon for students focused on machine learning. He has some great data from a retailer and interesting questions about customer purchase patterns. The challenge, however, is that he cannot disclose any personal data, and unfortunately for him high dimensional time-series data cannot be anonymized so easily. Indeed the simplest approaches, such as pseudonymization, are dangerously weak when it comes to time-series, because a purchase trajectory is almost a signature.
Synthetic data can help. Modern generative models can generate records with the same probability distribution as a given dataset. In our case, we are talking about a high dimensional distribution in a time-series space, which is a real challenge.
Because we are time-constrained and we tried to use a public LLM for the task.
In this post, we use a public time-series dataset to show that few-shot learning is not so easy to get right. But that, in contrast, fine-tuning is surprisingly powerful.
Few-Shot Learning from a Thousand Time Series
To test different approaches, we build a time-series dataset from a public dataset of hourly electricity consumption.
We then build a prompt with 10 examples:
We submit this prompt and get 10 generated series. Unfortunately, although not exactly equal, the generated series are almost identical to the ones we input.
After several unsuccessful attempts, some where the output format was not respected, some with shorter than expected series, some with totally random values, and because the length of the context forces me to select only a few example to teach GPT-4 to generate new examples, I realized few-shot learning may not be fit for the task.
It’s time to get back to the good old gradient descent, I will test OpenAI fine-tuning API.
Fine-Tuning GPT-3.5-turbo into a Specialized Time-Series Generator
Based on the same dataset (hourly electricity consumption), we generate a training split and a validation split suitable for the fine-tuning API.
We upload the files and launch the fine-tuning job.
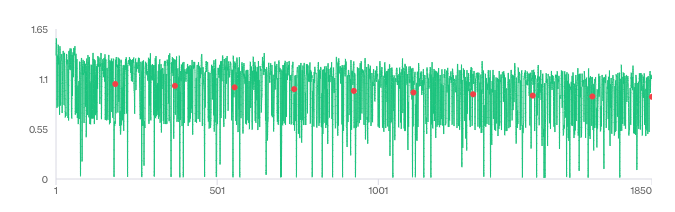
We can then generate new series:
The output looks rather good:
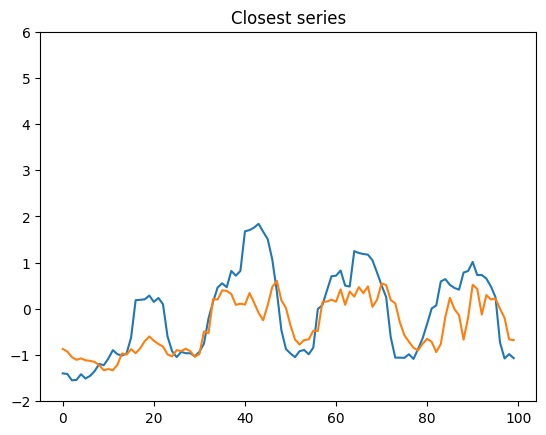
We can check that the generated series are all rather different from the series from the training set
By comparing each generated series to its closest element in the training dataset (closest in the l²-norm sense), we show that all the generated series are original (rather far from their closest element in the training set).
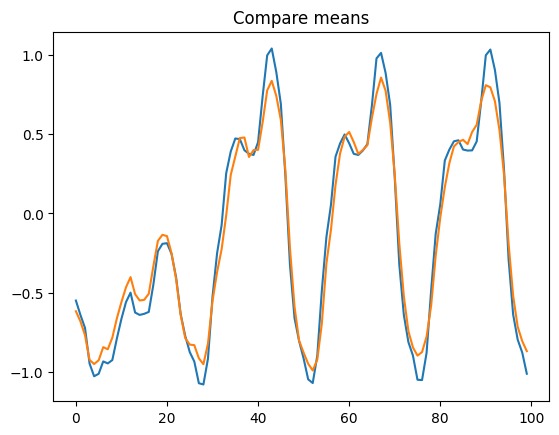
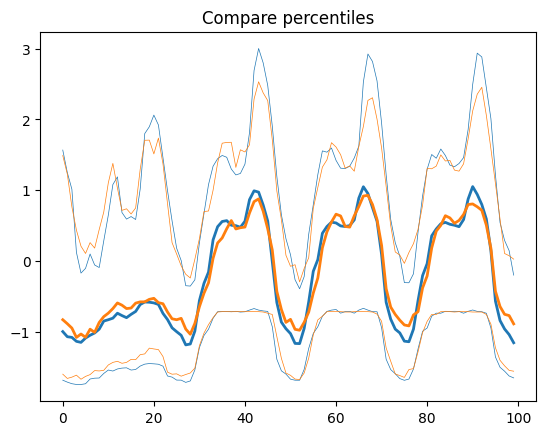
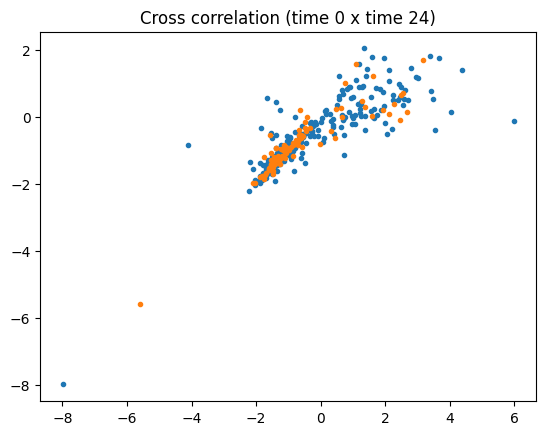
Nevertheless the generated data mimics most of the statistics of the training dataset
By computing basic statistics (mean, median, some percentiles) and some cross-correlations we show the generated series have a distribution relatively close to that of the original data.
Conclusion
Fine-tuning based synthetic data seem to show good statistical properties
Although this assertion would require much more investigations, it seems from the first quick descriptive statistics we computed that the synthetic data we generated represent quite faithfully the original distribution of data.
To go further we should compare how some typical downstream tasks (regressions, classifications, clustering) behave on both synthetic and original data to confirm this.
You can play with fine-tuning and few shot learning yourself
The notebooks are available on github.
Feel free to improve on this work and let us know what you found.
Our synthetic data does not contain any of the original confidential datapoints, but you need differential privacy for serious applications
We show by a quick similarity analysis that generated samples are all different from those in the original dataset. This is rather reassuring and gives some confidence in the fact privacy is relatively preserved.
Nevertheless, there is no formal guarantees privacy is actually protected. There are actually countless examples of reidentification attacks in the academic literature.
For very sensitive data you should rely on formal guarantees of privacy such as Differential Privacy. Sarus Technologies provides a service for LLM fine-tuning with differential privacy.
This post is one in a series of posts on AI and privacy. How to use AI and in particular commercial LLMs (for in-context learning, RAG or fine-tuning) with some privacy guarantees but also how AI and LLMs can help us solve privacy challenges. If you are interested in knowing more about existing AI with privacy solutions contact us and try our open-source framework: Arena (WIP).
See also:
.png)


